 I’m excited to unveil my latest consulting project, a fairly extensive RSS-based microsite put together with Sun Microsystems for next week’s JavaOne conference. It’s called BlogCentral. Turns out today is international RSS Awareness Day! This might have been a better fit for Enterprise RSS Awareness Day last week, but that’s ok.
I’m excited to unveil my latest consulting project, a fairly extensive RSS-based microsite put together with Sun Microsystems for next week’s JavaOne conference. It’s called BlogCentral. Turns out today is international RSS Awareness Day! This might have been a better fit for Enterprise RSS Awareness Day last week, but that’s ok.
I don’t often blog about particular consulting projects because most of the work I do is with pre-launch companies or for internal use only, but consulting is what I spend one to two thirds of my day doing after I finish blogging at ReadWriteWeb.
The Project
After building out a collection of RSS feeds that attendees could use to track the DEMO conference in January, I was approached by Sun about helping build a blog coverage microsite to track discussion of their giant JavaOne conference that starts next week.
This is an example of one end of the RSS spectrum, most use cases are far simpler – so don’t be scared!
JavaOne is a huge conference where scores of attendees will be blogging about a wide variety of Sun products and announcements. I worked with Sun to create a page called BlogCentral (hopefully to be moved to sun.com/blogcentral by conference time!) that aggregates all the latest and the most popular blog posts about the conference and 15 particular Sun projects and products. It’s like a news dashboard for anyone interested in seeing what’s being written about at JavaOne.
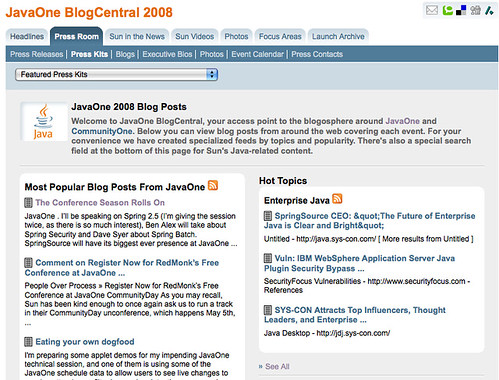
How We Did It
The project ended up being more complicated than I expected but it became relatively simple once I figured out the workflow on my end. I’ll describe it here in detail so that you can do something similar for other events or topics, if you like. Of course you can hire me to make it happen, but here’s a How-to in case you want to do it yourself -you can also just hire me so we can do something else magical together!
Step One: Build the Queries
For the conference in general and for 15 other topics, we used Google Blogsearch to search for blog mentions. For each topic we got a list of keywords that would indicate a post was concerning that topic, then we experimented with different queries strung together using AND, OR and – (not). We ended up with queries like:
“Mobile & Embedded” OR “Mobile and embedded” AND (JavaOne OR CommunityOne)
Did you know you could use parentheses in search queries in Google? I didn’t. Some of the queries were much longer and more complex so at several steps of the way we had to check to make sure the full query made it through the search. Once we saw the basic structure of the search results page URL we could often just make changes there. We used -“Re:” to remove the frequent forum postings.
We used advanced search to get 50 results per page and limit the searches to English language sources (per client request).
Google Blogsearch worked best because it gave the most complete, up to date results. There was a little more spam that had to be filtered out by query than was in Ask.com blogsearch (my usual favorite) but Ask pulled in a lot of press release feeds too.
Unfortunately Google doesn’t deliver the original blog source name in the RSS feed for results. That would have been nice to display on the final page. Blogdigger does deliver the source name but it always publishes “via Blogdigger” as well and the results aren’t nearly as extensive.
Removing the HTML in Titles
Google highlights your search terms in titles and summaries and in at least some cases the feed delivers the bold tags as tags. That looked pretty ugly on the page and was a real pain to remove. I asked friends on Twitter for suggestions and a lot of people tried to help me remove the markup with Yahoo Pipes. Unfortunately, as Yahoo! staff confirmed when I asked them, Pipes has an error with its Regex, the function that should have let me get a new feed with that markup removed. It took awhile to figure that out, I was sure I was doing something wrong! Update: See this Pipe it turns out to remove the bold text. Thanks Yahoo!
Instead, I ended up using my beloved Dapper.net to remove the markup, which was relatively easy using this Dapp. Just swithc out the input URL, identify the title as title and summary as item text and then create a short URL for the service. Note – you should check the “fix date” box for each feed, too, as otherwise Google Blogsearch doesn’t want to give you a publish date for the latest posts and that will mess up future steps. That short URL works as an RSS feed. Then refresh the page and repeat for other queries. Thanks again, Dapper!
Removing Duplicate Items
At this point I took my new RSS URL and went one of two directions. For the full feed of search results for each topic, I wanted to remove duplicate items. For this I went to Feed.Informer (formerly called FeedDigest) and chose to remove duplicates by URL, ignoring anchor links – so that blog comment URLs would get removed once the original post was seen.
This left me with a new RSS URL that I then took to Sun to put on the page.
Filtering for Hotness
From Dapper I also took the blogsearch feed URL over to AideRSS, where we got a new feed of just the 20% most commented on, linked-to and bookmarked blog posts in each search feed. That made up the Popular feed that you’ll see around the JavaOne Blogcentral page.
 I put the AideRSS folks through an awful lot but they were very helpful. Hopefully we got some kinks worked out of the system but keep in mind two things: if you can give them a short URL instead of a long one they’ll handle it better and second, almost any really crazy feed will error our the first time you input it. In the background, the processing is happening and if you come back later your ranked feed will be available. Huge thanks to AideRSS for doing something that no one else on the web does – give me a simple feed of the most high-value posts from one source, even a search feed. That is a big part of the value proposition of the final project and I really appreciate them for it.
I put the AideRSS folks through an awful lot but they were very helpful. Hopefully we got some kinks worked out of the system but keep in mind two things: if you can give them a short URL instead of a long one they’ll handle it better and second, almost any really crazy feed will error our the first time you input it. In the background, the processing is happening and if you come back later your ranked feed will be available. Huge thanks to AideRSS for doing something that no one else on the web does – give me a simple feed of the most high-value posts from one source, even a search feed. That is a big part of the value proposition of the final project and I really appreciate them for it.
FeedBurner
Ordinarily I would have run all of the above feeds through Feedburner as a final step. That would have let me change the source feed on the back end without ever having to send the client anything new. Sun didn’t want anything from Feedburner, though, because FB is blocked in China. That’s a real big shame.
Putting Those Puppies on the Page
We used the Planet software to display the most recent items in each feed on the page. It works well enough though I wasn’t terribly involved in this end and can’t say for sure how much granular control there is over feed display. Correction! Actually, that software was a customized version of Roller, I’m now told. Other options include (from most to least complex) MagpieRSS, SimplePie and Feed.Informer’s own output.
Custom Search Engine
While we were at it, we also put a Google Custom Search Engine that indexes just a handful of selected Sun domains on the bottom of the page. Added value with just minutes of extra work!
Conclusion
How’s that for RSS awareness? It’s pretty simple, really and once I got the markup removal figured out it was a lot of fun. My brain hurt at times, but that’s a good thing.
How did Sun feel about the project? Joanne Kisling, the person who brought me in on the project was kind enough to leave the following in comments here:
“I was Marshall’s contact at Sun and he was AWESOME to work with. He really knows his stuff. He dogged every detail and got answers, even when I was thinking we’d hit a dead end. I didn’t see the frustrated Tweets or anything like it; he was nothing but upbeat and pleasant despite some trying circumstances. I really like his determination and willingness to try new things. Great job, Marshall! ”
Thanks Joanne! Hopefully the description of the work above will help other folks do similar kinds of work with less frustration! I’m real happy though with how BlogCentral turned out.
Please feel free to ask any questions you have about the process, I’d love to give a quick bit of help if you’re trying to do something like this yourself. Of course if you’d like me to do something like this with you, availability is limited but drop me a line.
Happy RSS Awareness Day, everyone!