People have been saying for years that “data is the new oil” – but oil needs an engine. That analogy may break down, too, if data isn’t scarce but great engines are.
Analyst firm IDC released a series of reports on four parts of digital transformation yesterday and it could be looked at that way. I haven’t read it in full but I love the way it’s laid out and really appreciate that we’ve come to a place in history where this kind of model is valued as an asset.
Central to this model is not data, but an “intelligent core” that processes internal and external data.
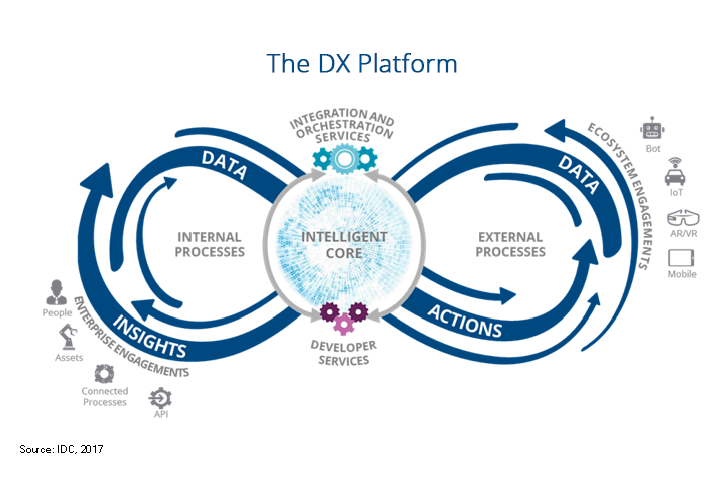
The model here, in narrative terms, is this: digital transformation is a cyclical process that runs internal engagements like data from instrumentation and insights from people, processes, assets and APIs, as well as external engagements like shared data and actions taken, through a central intelligent core. What’s in the core? Developer services so internal and external data can be worked with, and an orchestration layer to make sure everything keeps operating smoothly.
As data churns through that intelligent core, being processed by developers and being kept in sync with orchestrated processes, then it goes back out of the core into internal and external engagement, as new insights gleaned and new actions taken.
As I’m writing this, I’m in transit to visit a customer for which Sprinklr could totally be understood as providing the intelligent core for a substantial amount of this kind of digital transformation.
In this model, the data is important but the intelligent core is where the leverage comes in. IDC’s announcement quotes Meredith Whalen, senior vice president, thusly: “What is important to take away is that the data does not distinguish the company. It is what the company does with the data that distinguishes itself. How you build your intelligent core will determine your potential as an organization.”
That brings to mind something Jack Clark of OpenAI said on Twitter recently. He criticized the outdated belief that “Data is the most strategic thing” and argued instead that “compute is the most strategic thing. In the future we’re going to be using procedural environments/complex game simulations, so you get the data from your simulator and the strategic point comes from using compute to run it faster (aka generating more data). Another way to think about this is the rise of GAN [Generative Adversarial Network] techniques for data augmentation – you sample a distribution of initial data then you use compute to massively expand the available data via GANs, or whatever. Ultimately, compute trumps data.”
That’s probably taking it to a whole new level – arguing that the core could use AI techniques like Generative Adversarial Network AI to take a little bit of data and extrapolate out to build far more data to capture insights from. That’s cool to imagine.
Exciting times!